Uncovering the Hidden Truth: How to Find Outliers in Data
Uncovering the Hidden Truth: How to Find Outliers in Data
In today's data-driven world, spotting outliers is a crucial skill for anyone looking to gain a deeper understanding of their business, organization, or dataset. Outliers, whether they be data points, customers, or products, can hold the key to unlocking valuable insights and driving informed decision-making. In this article, we'll delve into the world of outlier detection, providing you with the tools and strategies needed to identify and interpret these anomalies. From the basics of outlier definition to cutting-edge machine learning techniques, we'll cover it all.
At its core, outlier detection is a process of identifying data points that significantly deviate from the norm. This can be applied to a wide range of fields, from finance and marketing to healthcare and manufacturing. According to Julien Cornebise, a data scientist at Capital One, "The ability to identify and understand outliers is essential in any industry where data is used to inform business decisions. By spotting outliers, you can uncover new opportunities, mitigate risks, and drive growth."
The Importance of Outlier Detection
Why Identify Outliers?
So why is outlier detection so crucial? For one, it allows you to identify and address potential issues before they become major problems. In finance, for example, detecting outliers in spending patterns can help prevent identity theft or credit card abuse. In marketing, spotting outliers in customer behavior can reveal new segments or opportunities for growth.
Furthermore, outlier detection can also help improve the accuracy and reliability of models and predictions. By identifying and removing outliers, you can reduce the impact of data quality issues and improve the overall robustness of your models.
Basic Statistical Methods for Outlier Detection
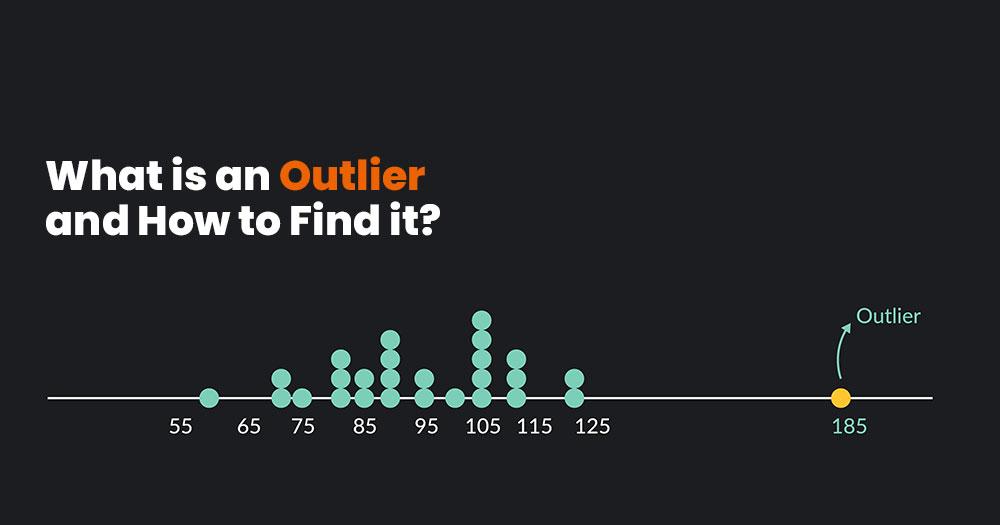
1. Visual Inspection
One of the simplest and most effective methods for outlier detection is visual inspection. By plotting your data, you can quickly identify unusual patterns or clusters that may indicate the presence of outliers.
For example, consider a company that collects customer ratings for a new product. A visual inspection of the data reveals a few ratings that are significantly higher or lower than the rest of the data. These outliers may indicate that the product is either extremely popular or has some major issues.
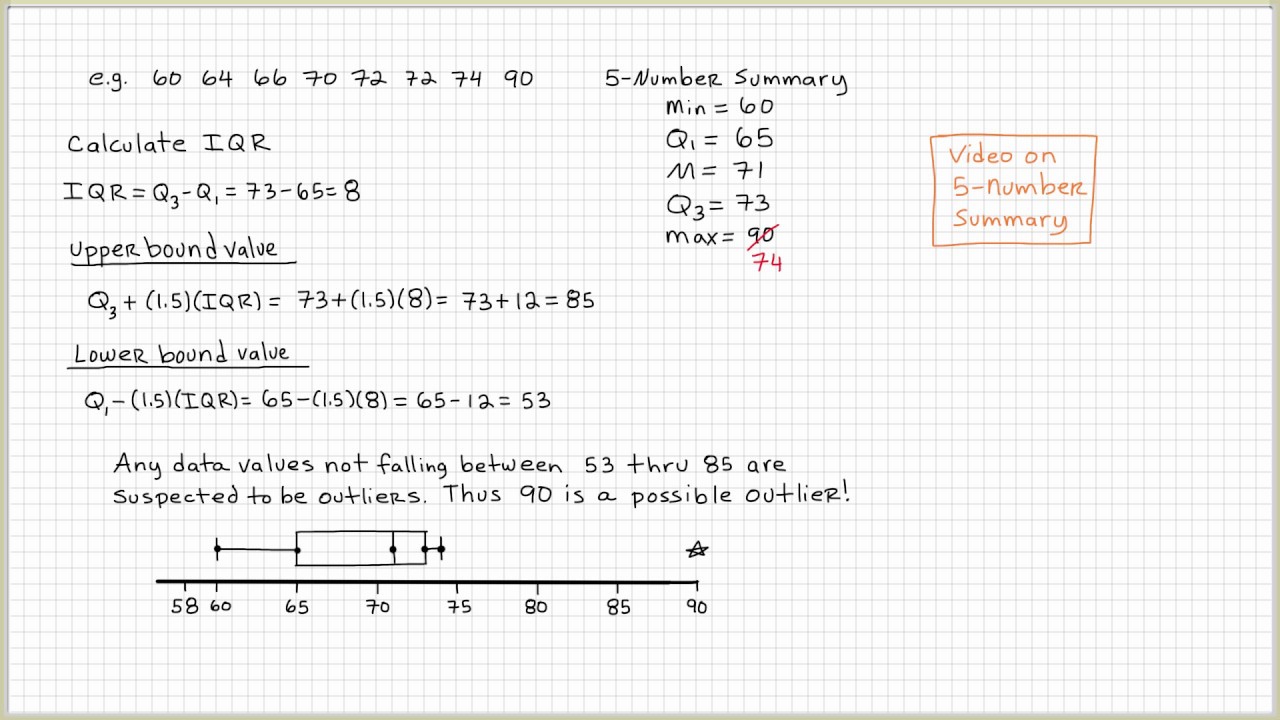
2. IQR (Interquartile Range)
Another basic method for outlier detection is the Interquartile Range (IQR). The IQR is the difference between the 75th percentile (Q3) and the 25th percentile (Q1) of the data. Any data point that falls below Q1 - 1.5*IQR or above Q3 + 1.5*IQR is considered an outlier.
For instance, let's say we have a dataset of exam scores with the following IQR: Q1 = 60, Q3 = 80. Using the IQR method, we would consider any score below 60 - 1.5*(80-60) or above 80 + 1.5*(80-60) to be an outlier.
3. Standard Deviation
Standard deviation is another commonly used method for outlier detection. By calculating the standard deviation of your data, you can identify data points that fall outside of a certain range, such as 2 standard deviations above or below the mean.
Consider a dataset of student heights with a mean of 175 cm and a standard deviation of 10 cm. Using the standard deviation method, we would consider any height above 175 + 2*10 or below 175 - 2*10 to be an outlier.
Machine Learning Techniques for Outlier Detection
While basic statistical methods are useful for initial outlier detection, they may not be effective for complex or high-dimensional data sets. In these cases, machine learning techniques can provide more accurate and robust outlier detection.
1. Isolation Forest
The Isolation Forest algorithm works by creating multiple instances of the data, each with a different feature subset. By analyzing the number of instances in which a data point is found in each subset, Isolation Forest can determine whether the data point is an outlier.
For example, consider a company that wants to identify outliers in customer behavior. Using Isolation Forest, the algorithm would create multiple subsets of customer data, each with a different feature (e.g., age, location, purchase history). By analyzing the frequency of each data point across the subsets, Isolation Forest can determine whether the point is an outlier.
2. One-Class SVM
The One-Class Support Vector Machine (SVM) is another machine learning technique for outlier detection. By training a SVM model on the data, you can identify areas of the data that are farthest from the mean, indicating potential outliers.
Let's say we have a dataset of stock prices with a distribution around the mean. By training a One-Class SVM model on the data, we can identify areas of the data that are farthest from the mean, indicating potential outliers such as unusually high or low prices.
3. Local Outlier Factor (LOF)
The Local Outlier Factor (LOF) algorithm calculates the similarity of each data point to its neighbors. By comparing the similarity of each data point to the average similarity of its neighbors, LOF can determine whether the data point is an outlier.
For instance, consider a company that wants to identify outliers in employee performance. Using LOF, the algorithm would calculate the similarity of each employee's performance to their coworkers. By comparing the similarity of each employee to the average similarity of their coworkers, LOF can determine whether the employee is an outlier.
Best Practices for Outlier Detection
1. Use Multiple Methods
When detecting outliers, it's essential to use multiple methods to ensure accuracy. By using a combination of statistical and machine learning techniques, you can increase the likelihood of identifying true outliers.
2. Visualize Your Data
Visualizing your data is a crucial step in outlier detection. By plotting your data, you can quickly identify unusual patterns or clusters that may indicate the presence of outliers.
3. Consider Domain Knowledge
When interpreting outliers, it's essential to consider domain knowledge and context. By understanding the underlying dynamics of your dataset, you can better identify and interpret outliers.
4. Continuously Monitor Your Data
Outliers can arise at any point in time, and it's essential to continuously monitor your data for new outliers. By setting up a regular outlier detection process, you can stay on top of potential anomalies and drive informed decision-making.
Conclusion
In conclusion, outlier detection is a vital skill for anyone working with data. By identifying and interpreting outliers, you can unlock new insights, drive growth, and mitigate risks. Whether you're a data scientist, analyst, or business leader, this guide has provided you with the tools and strategies needed to find and understand outliers in your data. Remember to use multiple methods, visualize your data, consider domain knowledge, and continuously monitor your data for new outliers. With these best practices in mind, you'll be well-equipped to uncover the hidden truth in your data and drive business success.


Related Post

Meteorologist Is Marvin Gomez Married: Uncovering the Life of America's Favorite Weatherman

Unleashing the Power of Next-Generation Computing: OSCYTSC Industries Capra Core 1 Takes Center Stage

Stepmom Blackmailed: The Hidden Epidemic of Emotional Manipulation



